

新功能将面向Plus和企业用户两周内上线。
来源|多知网
图片来源|OpenAI
多知网9月26日消息,OpenAI在其官网宣布,将在ChatGPT中推出新的语音和图像功能,这将提供了一种新的、更直观的界面,允许用户进行语音对话或向ChatGPT展示正在谈论的内容。
语音和图像让ChatGPT使用方法将更多元化,如在旅行时拍一张地标的照片发给ChatGPT,并就它的有趣之处进行实时对话。当回到家的时候,拍下冰箱和食品储藏室的照片,询问ChatGPT晚餐要吃什么,还可以追问,以获得一步一步的食谱。晚饭后,帮孩子做数学题,拍张照片,ChatGPT可以进行批改,并给出解释。
在接下来的两周内,OpenAI将向Plus和企业用户推出ChatGPT的语音和图像功能。语音支持iOS和Android,图像支持所有平台。
在Plus和企业用户推出之后,未来,语音和图像功能也会推出给其他用户组,包括开发人员。
01
如何使用语音和图像功能?
OpenAI还给出了一些示例和具体使用方法:
1、与ChatGPT用语音多轮对话
你现在可以使用语音与你的助手进行多轮对话。在路上和它说话,为你的家人定制一个睡前故事,或者在餐桌上进行辩论。
要开始使用语音,请前往移动应用程序的设置→新功能,并选择语音对话。然后,点击位于主屏幕右上角的耳机按钮,从五种不同的声音中选择您喜欢的声音。
新的语音功能由一个新的文本到语音模型提供支持,能够从文本和几秒钟的语音样本中生成类似人类的音频。OpenAI与专业的配音演员合作创造了每一个声音。OpenAI还使用了自己开源语音识别系统Whisper,将用户说的话转录成文本。
也就是说,可以让ChatGPT生成故事,然后语音读给全家人听。
在这里OpenAI还举了一个小例子:
故事中文大意:
从前,在一片宁静的森林里,有一只毛茸茸的猫妈妈,名叫Lila。一个阳光明媚的日子,她在一棵老橡树的树荫下,抱着她那顽皮的小猫Milo。
“Milo,”Lila开始说,她的声音温柔而温柔,“你很快就会有一个新玩伴了。”
“一个新玩伴?”Milo的耳朵竖起来,充满好奇。
“是的,一个小妹妹。”Lila咕噜着。
“妹妹?她会像我一样追逐尾巴吗?”Milo兴奋得睁大了眼睛。
“哦,她有她自己的怪癖。你会教她的,是吗?”Lila咯咯地笑了。
Milo急切地点了点头,已经开始幻想他们将一起经历的冒险。
2、讨论图片
现在可以向ChatGPT显示一个或多个图像。比如,排除你的烤架无法启动的原因,探索冰箱里的东西来计划吃什么饭,或者分析与工作相关的复杂图表。有一些图像的特定部分如果需要画圈、截图等,还可以使用OpenAI移动应用程序中的绘图工具。
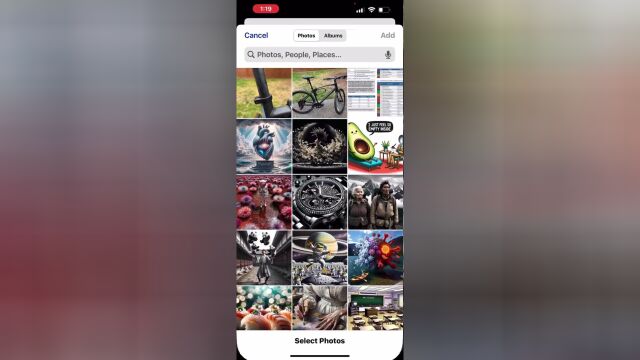
可以点击照片按钮来捕获或选择图像。如果你用的是iOS或Android,先点击加号键。您也可以讨论多个图像或使用绘图工具。
图像理解由多模态GPT-3.5和GPT-4提供支持。这些模型将它们的语言推理技能应用于各种各样的图像,例如照片、屏幕截图和同时包含文本和图像的文档。
02
研发图像和语音功能的背后逻辑
OpenAI提到,正在逐步部署图像和语音功能。
OpenAI的目标是构建安全和有益的AGI。“我们相信我们的工具是逐步可用的,这使我们能够随着时间的推移进行改进和完善风险缓解,同时也为每个人在未来更强大的系统做好准备。这一策略在涉及语音和视觉的高级模型中变得更加重要。”OpenAI提到。
在声音方面,这项新的语音技术能够从几秒钟的真实语音中制作出逼真的合成声音,为许多创造性和可访问性的应用打开了大门。然而,这些功能也带来了新的风险,例如有些恶意分子可能会冒充公众人物或实施欺诈行为。
这就是为什么OpenAI使用这项技术来支持一个特定的用例——语音聊天。语音聊天是由OpenAI直接合作过的配音演员创建的。未来也以类似的方式与其他人合作。例如,Spotify正在利用这项技术的力量为他们的语音翻译功能试点,这有助于播客主持人通过使用播客主持人自己的声音将播客翻译成更多语言来扩大他们的讲述。
图像输入
基于视觉的模型也带来了新的挑战,从对人们的幻想到依赖模型对图像的解释这类高风险领域。在更广泛的部署之前,OpenAI使用红队测试员测试了高风险领域的模型,如极端主义和科学能力,以及各种alpha测试者。
使图片功能既有用又安全
像ChatGPT的其他功能一样,视觉是关于帮助用户的日常生活。当它能看到用户看到的东西时,它会做得最好。
这种方法直接来自于OpenAI与Be My Eyes的合作,Be My Eyes 是一个为盲人和低视力人士提供的免费移动应用程序,以了解使用和局限性。用户告诉OpenAI,当背景中出现人物时(例如,当您试图搞清遥控器设置时,电视上出现某人),他们会发现就图像进行对话很有价值。
OpenAI称,我们还采取了技术措施,显著限制了ChatGPT对人员的分析和直接陈述的能力,因为ChatGPT不总是准确的,而这些系统应该尊重个人的隐私。
关于模型局限性的透明度
用户可能会依赖ChatGPT进行特定的专题,例如研究等领域。OpenAI对模型的局限性保持透明,并阻止在没有适当验证的情况下使用高风险用例。此外,该模型善于转录英语文本,但在某些其他语言(尤其是非罗马字母的语言)上的表现较差。OpenAI建议非英语用户不要将ChatGPT用于此目的。
值得注意的是,大模型多模态发展一定是趋势,目前,我国的大模型有的有语音功能,有的有图片功能,不过,功能尚简单,仍处于快速迭代之中。
在不久的将来,大模型的多模态化将有更多的应用场景落地。

